Getting started with INTEGRATE¶
This notebook contains a simple example for getting started with INTEGRATE.
The workflow follows these main steps:
Load electromagnetic data (DAUGAARD.h5) 1a. Set up a prior model, creating the file PRIOR.h5 1b. Update the prior model with forward-modeled data in PRIOR.h5
Perform probabilistic inversion using integrate_rejection, creating POST.h5
Plot and analyze the results
[1]:
try:
# Check if the code is running in an IPython kernel (which includes Jupyter notebooks)
get_ipython()
# If the above line doesn't raise an error, it means we are in a Jupyter environment
# Execute the magic commands using IPython's run_line_magic function
get_ipython().run_line_magic('load_ext', 'autoreload')
get_ipython().run_line_magic('autoreload', '2')
except:
# If get_ipython() raises an error, we are not in a Jupyter environment
# # # # # # #%load_ext autoreload
# # # # # # #%autoreload 2
pass
[2]:
import integrate as ig
# Check if parallel computations can be performed
parallel = ig.use_parallel(showInfo=1)
hardcopy = True
import matplotlib.pyplot as plt
import numpy as np
Notebook detected. Parallel processing is OK
0. Get TTEM data¶
Several test cases are available in the INTEGRATE package. To see which cases are available, check the get_case_data function.
The code below downloads the file DAUGAARD_AVG.h5 that contains TTEM (time-domain electromagnetic) soundings from Daugaard, Denmark. It also downloads the corresponding GEX file, TX07_20231016_2x4_RC20-33.gex, which contains information about the TTEM system configuration and parameters.
[3]:
case = 'DAUGAARD'
files = ig.get_case_data(case=case, showInfo=2)
f_data_h5 = files[0]
file_gex= ig.get_gex_file_from_data(f_data_h5)
print("Using data file: %s" % f_data_h5)
print("Using GEX file: %s" % file_gex)
Getting data for case: DAUGAARD
File DAUGAARD_AVG.h5 already exists. Skipping download.
File TX07_20231016_2x4_RC20-33.gex already exists. Skipping download.
File README_DAUGAARD already exists. Skipping download.
--> Got data for case: DAUGAARD
Using data file: DAUGAARD_AVG.h5
Using GEX file: TX07_20231016_2x4_RC20-33.gex
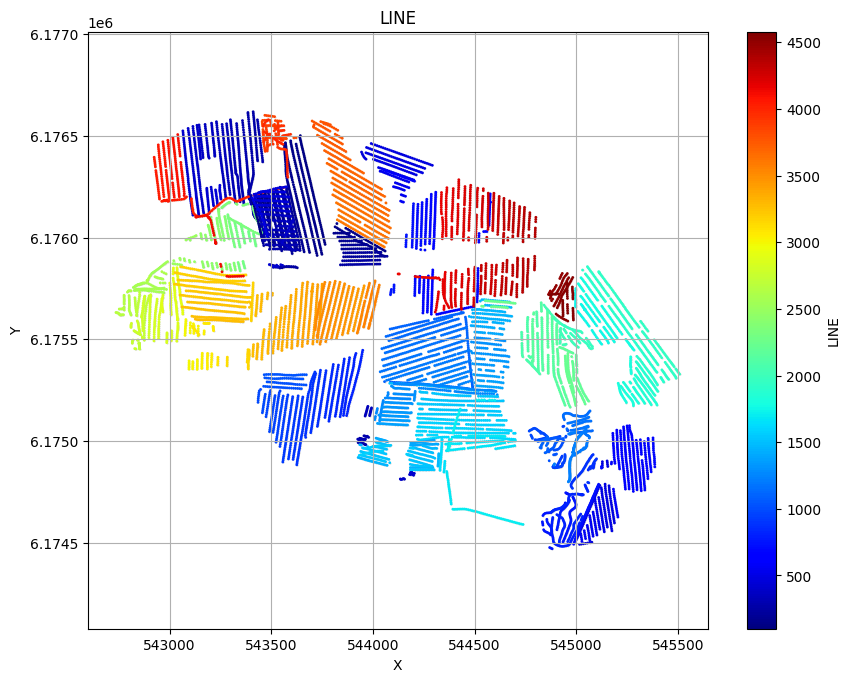
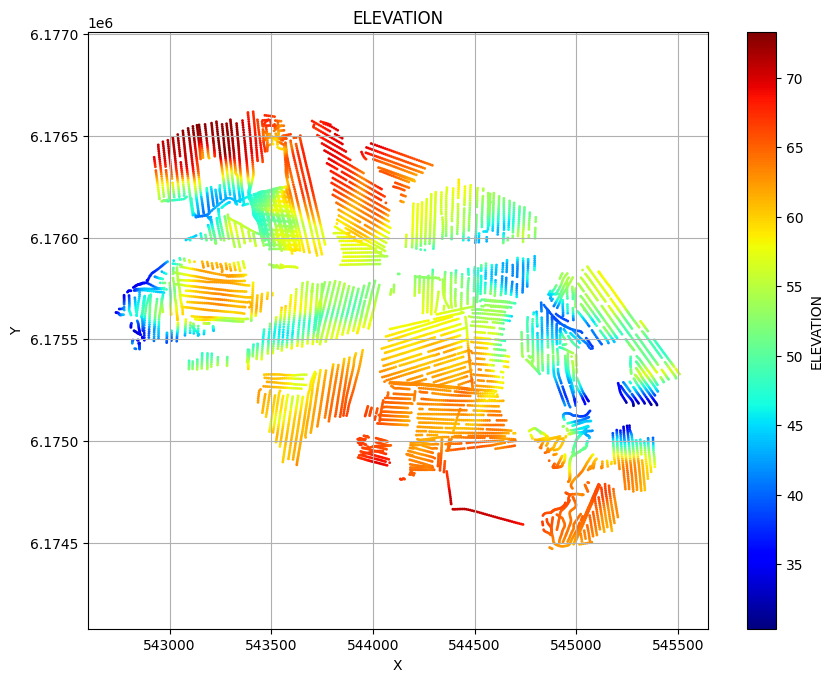
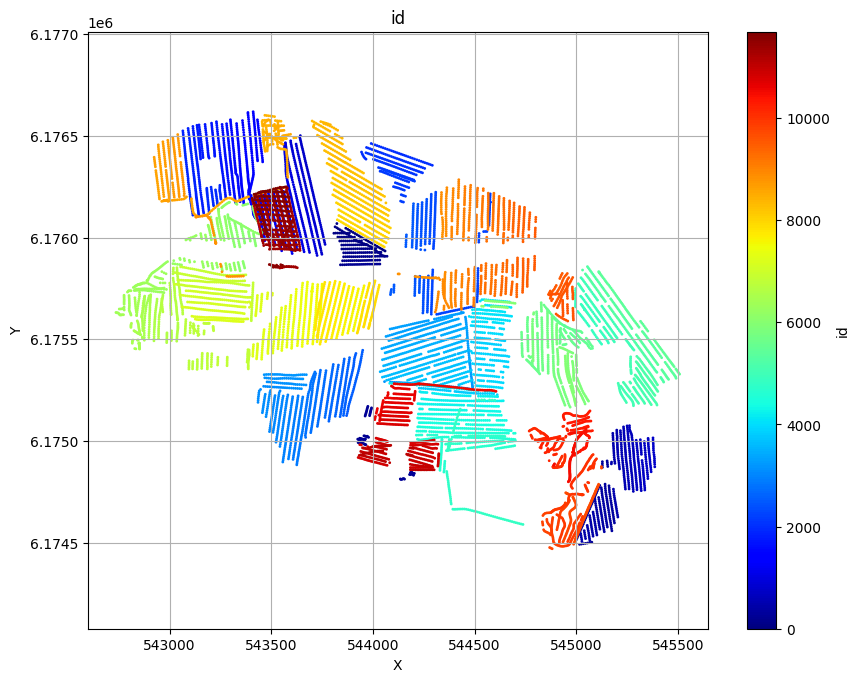
Plot the geometry and data¶
ig.plot_geometry plots the spatial geometry of the data (i.e., the locations of the soundings). ig.plot_data plots the measured electromagnetic data for each sounding.
[4]:
# The commented line below would plot LINE, ELEVATION and data id as three scatter plots:
# ig.plot_geometry(f_data_h5)
# Each plot can be generated separately by specifying the 'pl' argument:
ig.plot_geometry(f_data_h5, pl='LINE')
ig.plot_geometry(f_data_h5, pl='ELEVATION')
ig.plot_geometry(f_data_h5, pl='id')
f_data_h5=DAUGAARD_AVG.h5
f_data_h5=DAUGAARD_AVG.h5
f_data_h5=DAUGAARD_AVG.h5
[5]:
useSubset = False
X, Y, LINE, ELEVATION = ig.get_geometry(f_data_h5)
# Find points within buffer distance
Xl = np.array([544000, 543550])
Yl = np.array([6174500, 6176500])
#Xl = np.array([544000, 543550, 543000])
#Yl = np.array([6174500, 6176500, 6176400])
buffer = 10.0
indices, distances, segment_ids = ig.find_points_along_line_segments(
X, Y, Xl, Yl, tolerance=buffer
)
i_line = indices
if useSubset:
i_use = i_line
plt.figure()
ig.plot_geometry(f_data_h5, pl='ELEVATION')
plt.plot(Xl, Yl,'ko', markersize=15)
plt.plot(X[i_use], Y[i_use], 'ko', markersize=5)
plt.title('Profile line')
plt.show()
else:
# Use all data 1:len(X)
i_use = np.arange(len(X))
[6]:
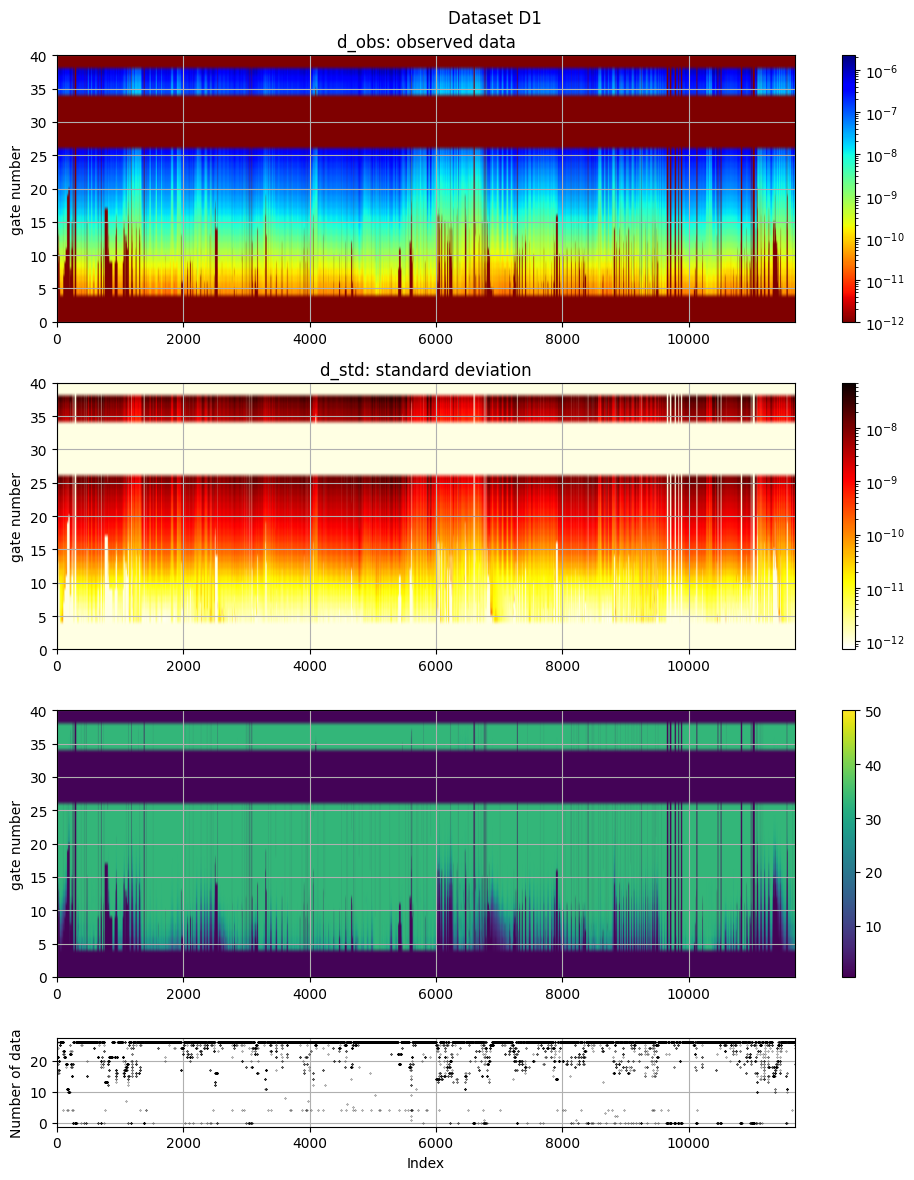
# The electromagnetic data (d_obs and d_std) can be plotted using ig.plot_data:
ig.plot_data(f_data_h5, hardcopy=hardcopy)
# Plot data channel 15 in an XY grid
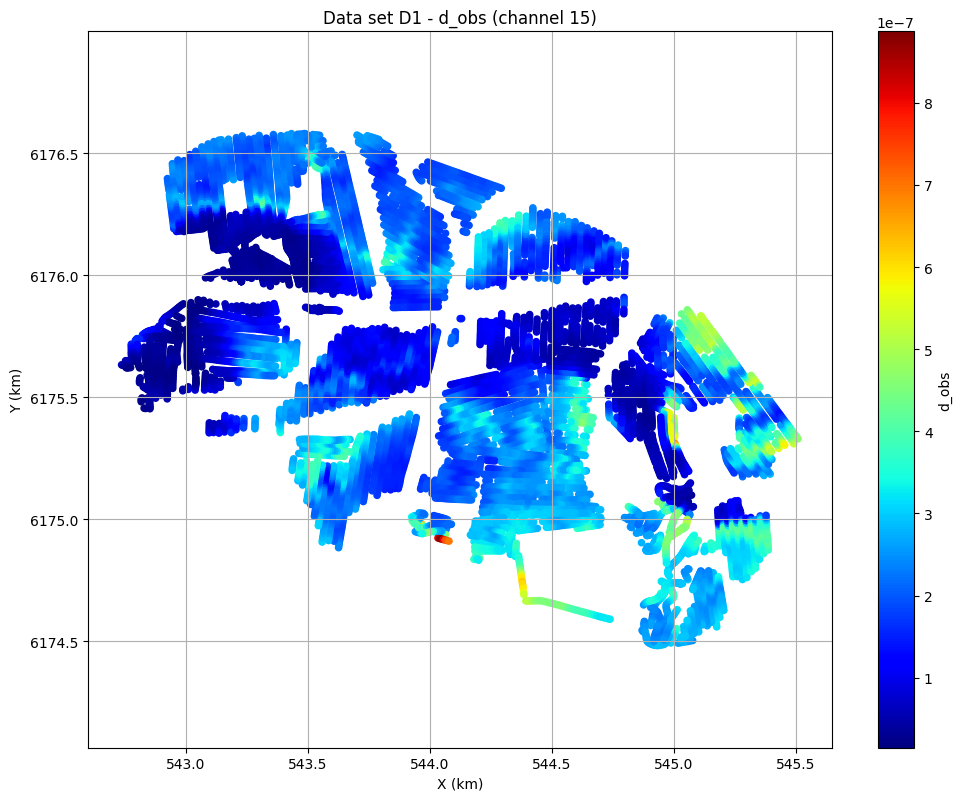
ig.plot_data_xy(f_data_h5, data_channel=15, cmap='jet');
plot_data: Found data set D1
plot_data: Using data set D1
1. Set up the prior model (\(\rho(\mathbf{m},\mathbf{d})\))¶
In this example, a simple layered prior model will be considered. The prior represents our initial beliefs about subsurface resistivity structure.
1a. Generate prior model parameters¶
First, we generate a sample of the prior model parameters, \(\rho(\mathbf{m})\).
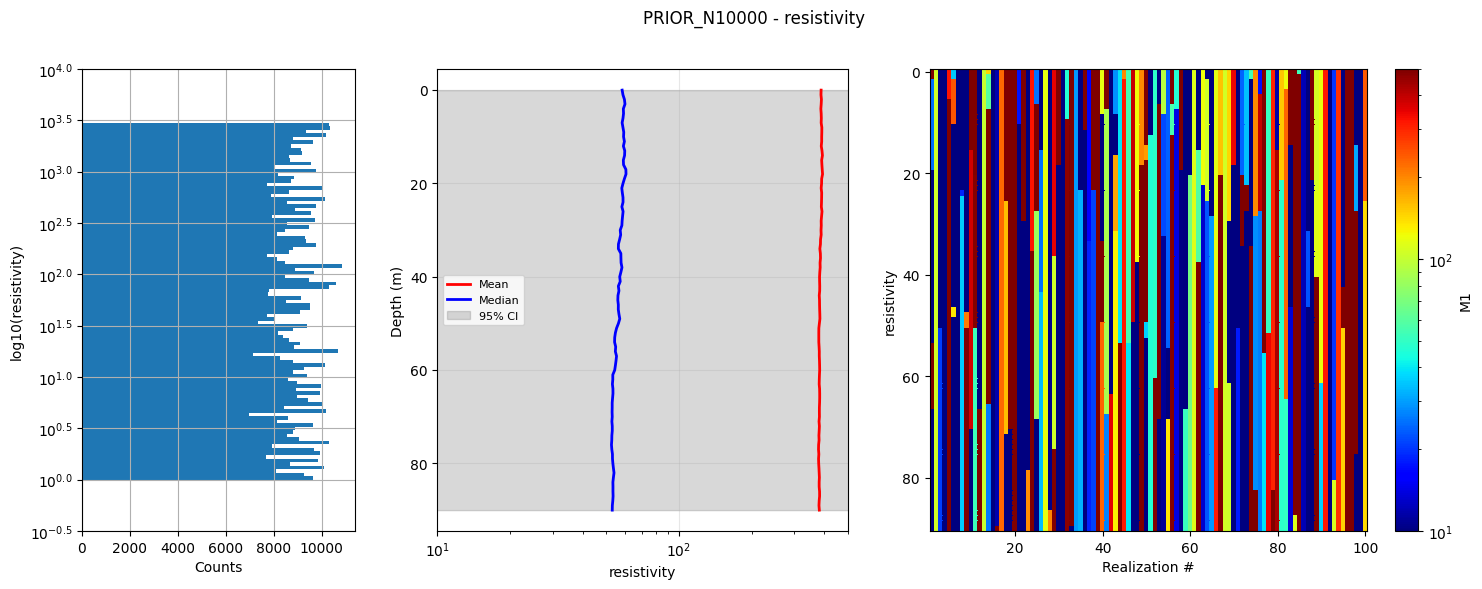
As an example, we choose a simple layered Earth model. The number of layers follows a chi-squared distribution with 4 degrees of freedom, and the resistivity in each layer is log-uniformly distributed between [1,3000] Ωm.
This creates N realizations of 3 types of model parameters:
PRIOR:/M1: 1D resistivity values in 1m thick layers down to 90m depth
PRIOR:/M2: 1D resistivity values in discrete parameter sets where the first
Nlayer parameters are resistivities, and the last Nlayer-1
parameters are depths to the base of each layer
PRIOR:/M3: The number of layers in each model realization
[7]:
# Select how many prior model realizations (N) should be generated
N=2000000
N=10000
f_prior_h5 = ig.prior_model_layered(N=N,lay_dist='chi2', NLAY_deg=3, RHO_min=1, RHO_max=3000, f_prior_h5='PRIOR_N%d.h5' % N,
showInfo=1)
#print('%s is used to hold prior realizations' % (f_prior_h5))
prior_model_layered: Saving prior model to PRIOR_N10000.h5
File PRIOR_N500000.h5 does not exist.
PRIOR_N500000.h5 is used to hold prior realizations
[8]:
# Plot summary statistics of the prior model for quality control of the prior choice
ig.plot_prior_stats(f_prior_h5, hardcopy=hardcopy)
1b. Generate corresponding prior data¶
Next, we generate a corresponding sample of \(\rho(\mathbf{d})\) (prior data distribution).
The prior data, corresponding to the prior model parameters, are computed using the GA-AEM electromagnetic forward modeling code and the GEX system configuration file.
[9]:
# Option 1: Update the existing PRIOR.h5 file with forward-modeled data
# set the default hdf file to be the f_prior_data_h5 (without extension) + file_gex (without extension) + .h5
f_prior_data_h5 = '%s_%s_Nh280_Nf12.h5' % (f_prior_h5[:-3], file_gex[:-4])
useExistingData = True
if useExistingData:
# if exist f_post_data_h5 then used it, otherwise create it
import os
if not os.path.exists(f_prior_data_h5):
f_prior_data_h5 = ig.prior_data_gaaem(f_prior_h5, file_gex, doMakePriorCopy=True, f_prior_data_h5=f_prior_data_h5, parallel=parallel)
else:
print('Using existing prior data file: %s' % f_prior_data_h5)
#f_prior_data_h5 = ig.prior_data_gaaem(f_prior_h5, file_gex, doMakePriorCopy=False, parallel=parallel)
#f_prior_data_h5 = ig.prior_data_gaaem(f_prior_h5, file_gex, parallel=False)
print('Updated %s to hold prior data (forward-modeled responses)' % (f_prior_data_h5))
Using existing prior data file: PRIOR_N10000_TX07_20231016_2x4_RC20-33_Nh280_Nf12.h5
Updated PRIOR_N10000_TX07_20231016_2x4_RC20-33_Nh280_Nf12.h5 to hold prior data (forward-modeled responses)
prior_data_gaaem: Time=662.8s/500000 soundings. 1.3ms/sounding, 754.4it/s
Updated PRIOR_N500000_TX07_20231016_2x4_RC20-33_Nh280_Nf12.h5 to hold prior data (forward-modeled responses)
[10]:
D = ig.load_prior_data(f_prior_data_h5)[0][0]
Loading prior data from PRIOR_N10000_TX07_20231016_2x4_RC20-33_Nh280_Nf12.h5. Using prior data ids: []
- /D1: N,nd = 10000/40
- /D1: N,nd = 500000/40
It is useful to compare the prior data to the observed data before inversion. If there is little to no overlap between observed and prior data, the inversion is unlikely to succeed, indicating inconsistency between the prior model and observations. In the figure below, you can see that the observed data (red) falls clearly within the range of the prior data distribution.
[11]:
ig.plot_data_prior(f_prior_data_h5,f_data_h5,nr=1000,hardcopy=hardcopy)
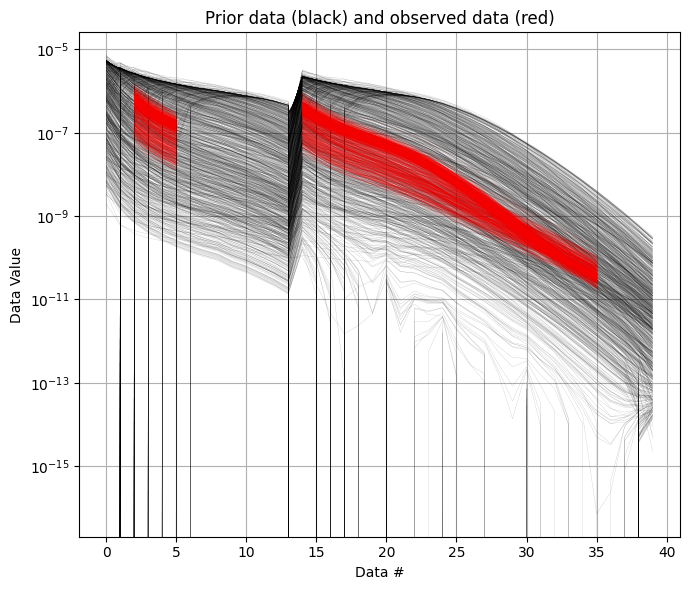
[11]:
True
2. Sample the posterior distribution \(\sigma(\mathbf{m})\)¶
The posterior distribution is sampled using the extended rejection sampler.
[12]:
# Rejection sampling of the posterior can be done with default settings using:
#f_post_h5 = ig.integrate_rejection(f_prior_h5, f_data_h5)
# However, you can control several important options.
# You can choose to use only a subset of the prior data. Decreasing the sample
# size makes the inversion faster but increasingly approximate.
N_use = N # Number of prior samples to use (use all available)
T_base = 1 # Base annealing temperature for rejection sampling
autoT = 1 # Automatically estimate optimal annealing temperature
f_post_h5 = ig.integrate_rejection(f_prior_data_h5,
f_data_h5,
f_post_h5 = 'POST.h5',
N_use = N_use,
autoT = autoT,
T_base = T_base,
showInfo=0,
parallel=parallel,
ip_range=i_use)
integrate_rejection: Time= 18.0s/11693 soundings, 1.5ms/sounding, 649.2it/s. T_av=137.8, EV_av=-128.4
integrate_rejection: Time=736.9s/11693 soundings, 63.0ms/sounding, 15.9it/s. T_av=22.7, EV_av=-47.7
Computing posterior statistics for 11693 of 11693 data points
Creating /M1/Mean in POST.h5
Creating /M1/Median in POST.h5
Creating /M1/Std in POST.h5
Creating /M1/LogMean in POST.h5
Creating /M2/Mean in POST.h5
Creating /M2/Median in POST.h5
Creating /M2/Std in POST.h5
Creating /M2/LogMean in POST.h5
Creating /M3/Mean in POST.h5
Creating /M3/Median in POST.h5
Creating /M3/Std in POST.h5
Creating /M3/LogMean in POST.h5
[13]:
# Posterior statistics computation (typically done after inversion)
# This computes summary statistics like mean, median, standard deviation
# ig.integrate_posterior_stats(f_post_h5)
# ig.integrate_posterior_stats(f_post_h5, ip_range = i_use)
3. Plot statistics from the posterior \(\sigma(\mathbf{m})\)¶
Compare prior and posterior data¶
First, compare prior (beige) to posterior (black) data, along with observed data (red), for specific measurement locations (data IDs).
[14]:
ig.plot_data_prior_post(f_post_h5, i_plot=100,hardcopy=hardcopy)
ig.plot_data_prior_post(f_post_h5, i_plot=i_use[0],hardcopy=hardcopy)
ig.plot_data_prior_post(f_post_h5, i_plot=i_use[-1],hardcopy=hardcopy)
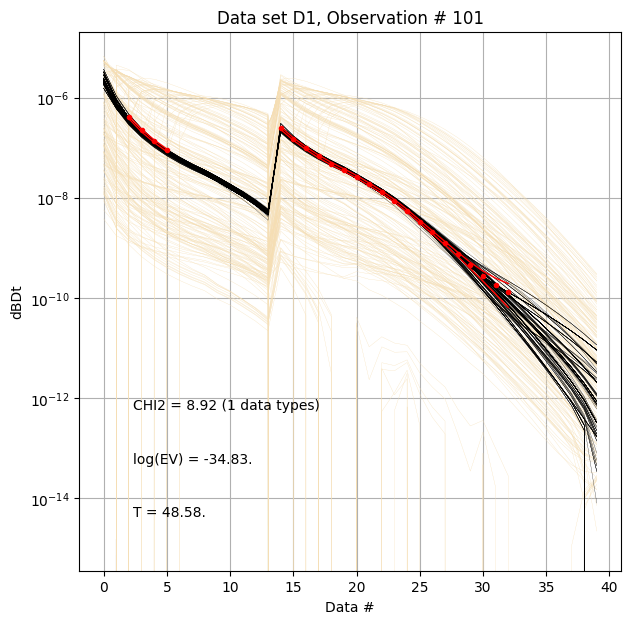
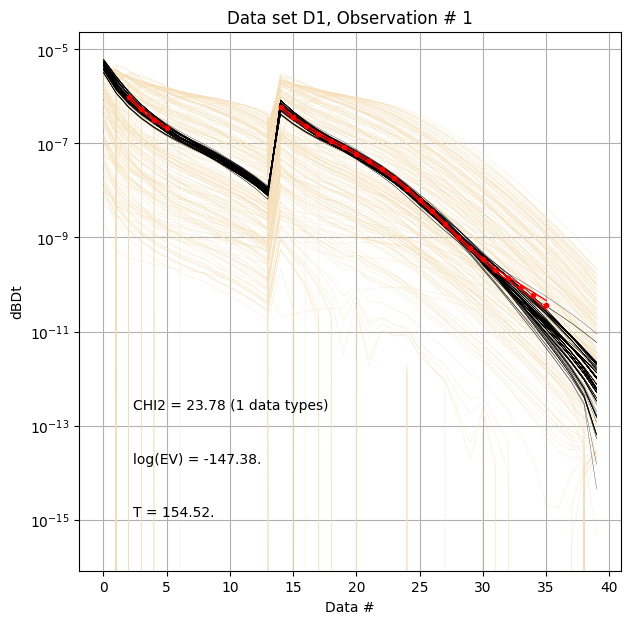
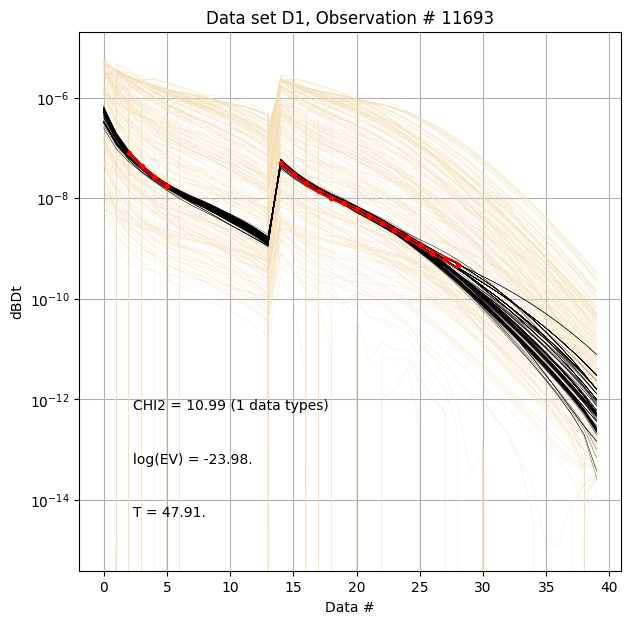
Evidence and annealing temperature¶
The evidence quantifies how well the data fits the model, while temperature controls the acceptance rate in rejection sampling.
[ ]:
# Plot the annealing temperature used for inversion
ig.plot_T_EV(f_post_h5, pl='T',hardcopy=hardcopy)
# Plot the evidence (log-likelihood) estimated during inversion
ig.plot_T_EV(f_post_h5, pl='EV',hardcopy=hardcopy)
# Plot the chi-squared data fit (normalized mean-loglikelihood)
# Values less than one suggest overfitting
# Values above one suggest underfitting
ig.plot_T_EV(f_post_h5, pl='CHI2',hardcopy=hardcopy)
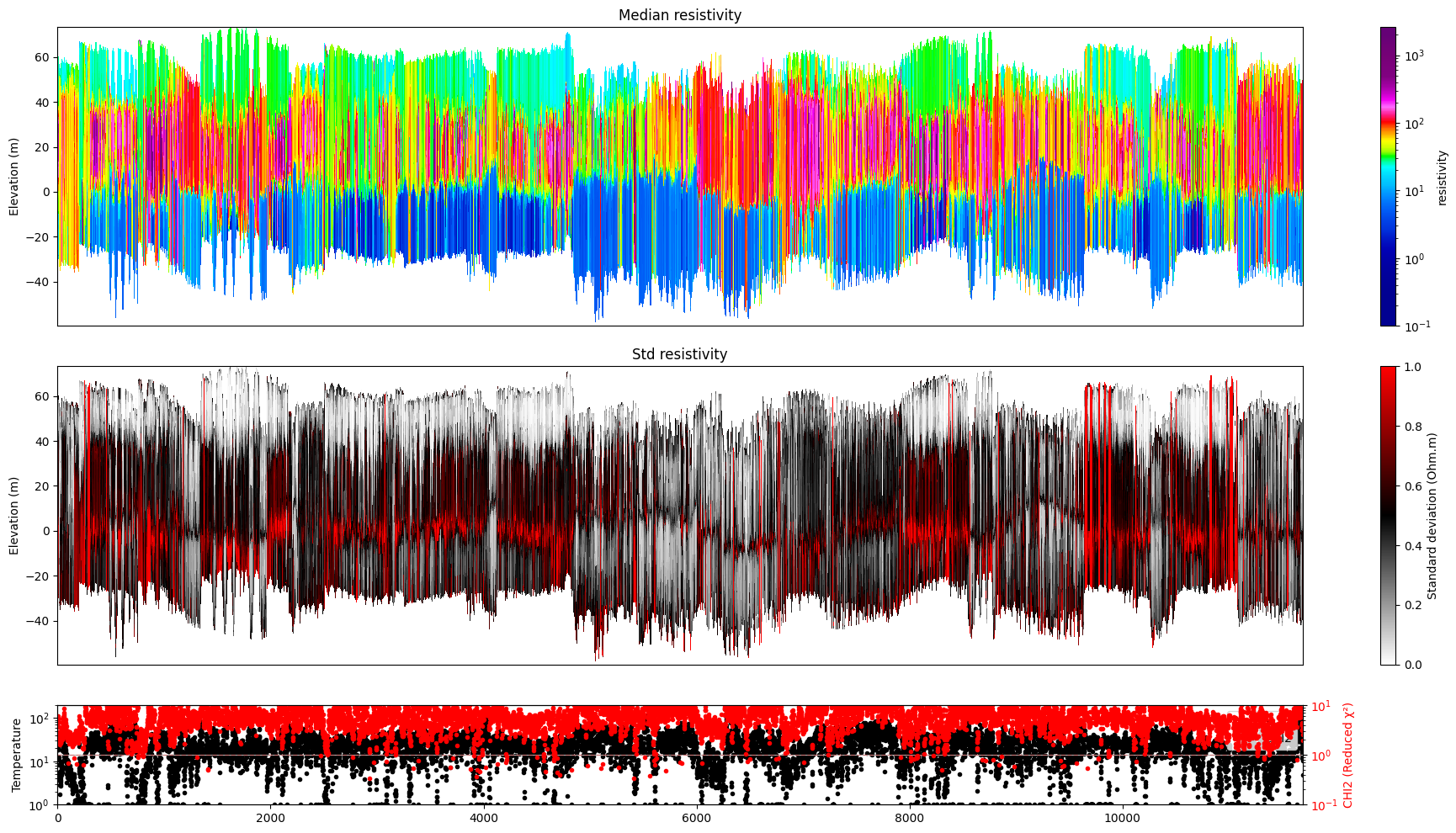
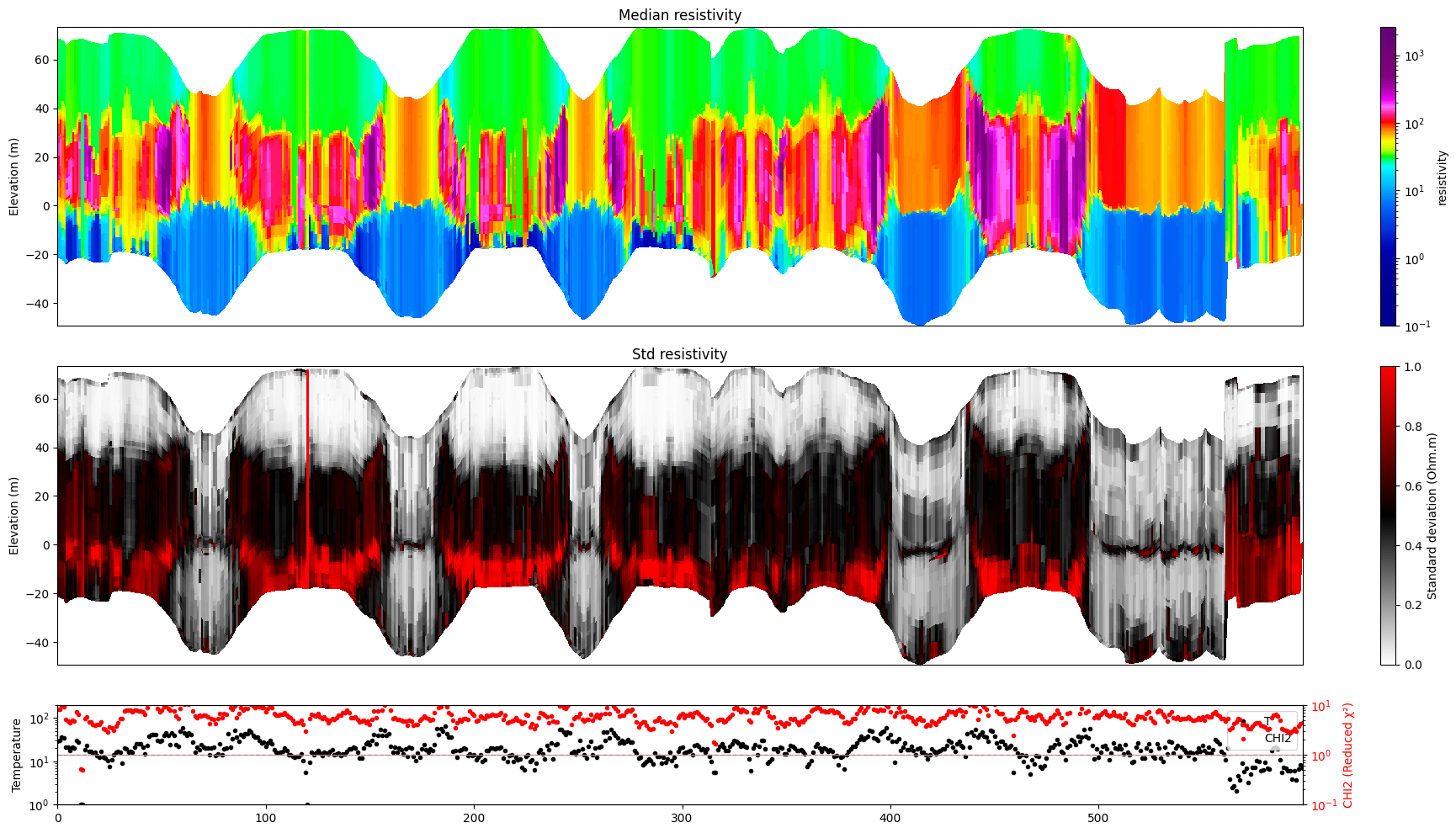
Resistivity profiles¶
Plot a profile showing posterior statistics of model parameter M1 (resistivity) along a section of the survey line.
[16]:
# Plot resistivity profile for model M1
ig.plot_profile(f_post_h5, im=1, hardcopy=hardcopy)
# Plot resistivity profile for model M1 from data point i1 to i2
ig.plot_profile(f_post_h5, i1=1401, i2=2000, im=1, hardcopy=hardcopy)
if useSubset:
# Plot resistivity profile for model M1 for specific data points, along 'x', 'y' and 'index' axes
ig.plot_profile(f_post_h5, ii=i_use, im=1, hardcopy=hardcopy, xaxis='x')
ig.plot_profile(f_post_h5, ii=i_use, im=1, hardcopy=hardcopy, xaxis='y')
ig.plot_profile(f_post_h5, ii=i_use, im=1, hardcopy=hardcopy, xaxis='index')
#
ig.plot_profile(f_post_h5, ii=i_use, im=1, hardcopy=hardcopy, xaxis='index', panels=['Median'])
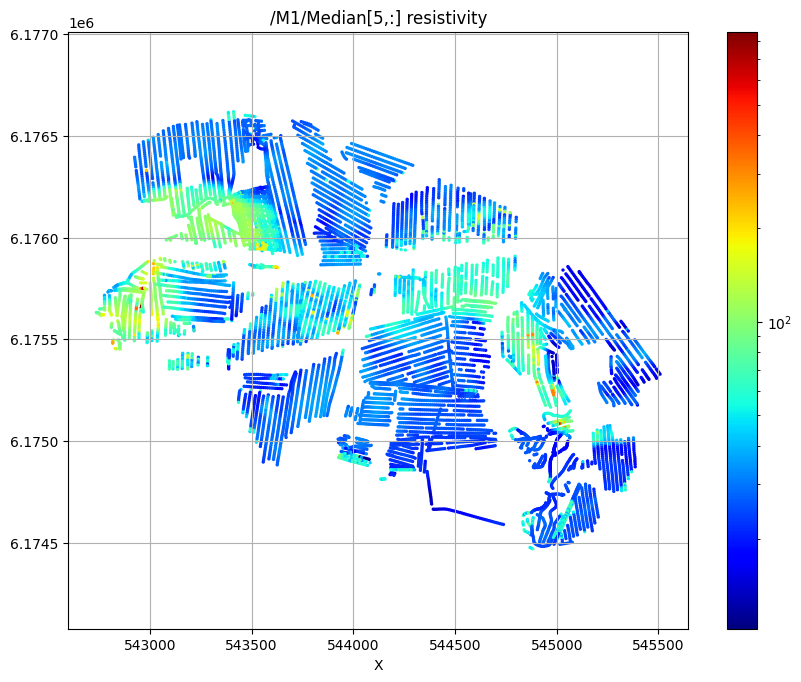
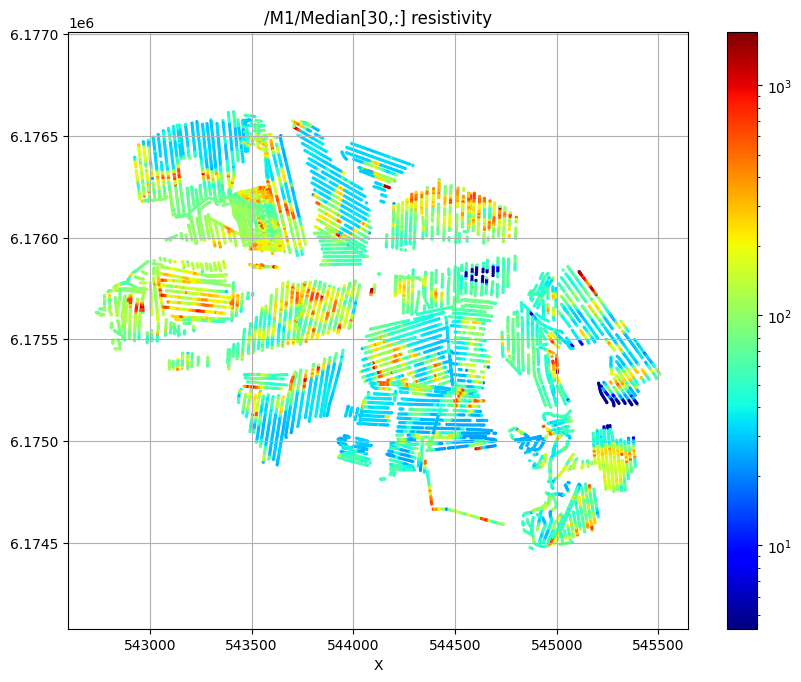
Plot 2D spatial features¶
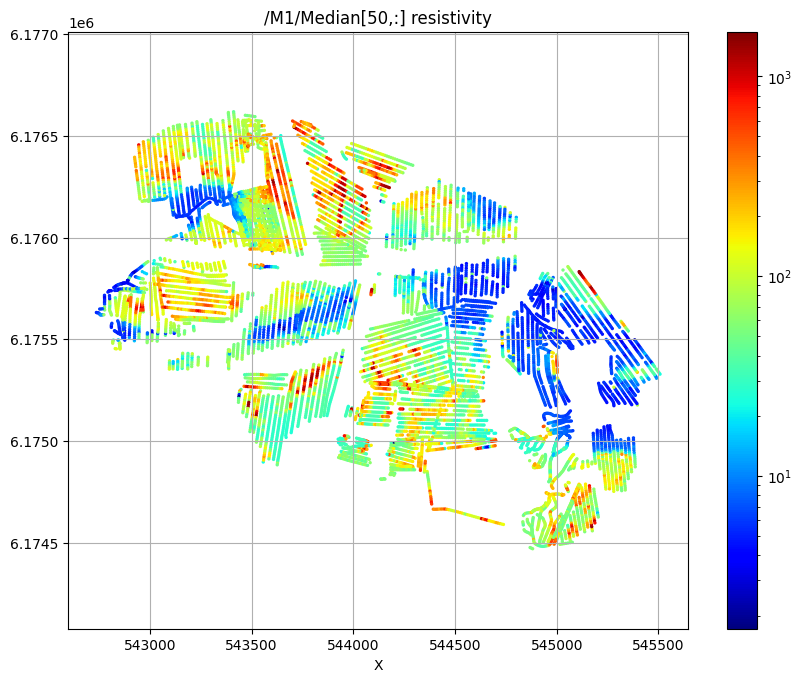
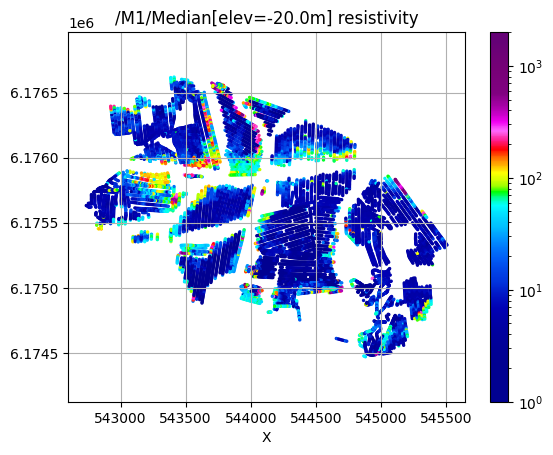
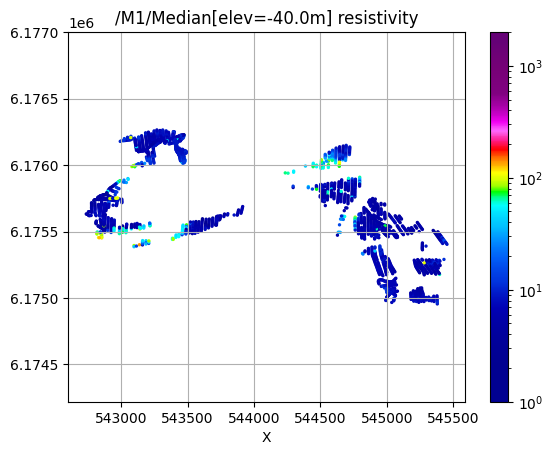
Plot the median resistivity at specific depths (layers 5, 30, and 50) to show lateral variations in subsurface structure.
[17]:
# Plot 2D features: Resistivity at different depths
try:
ig.plot_feature_2d(f_post_h5,im=1,iz=5, key='Median', uselog=1, cmap='jet', s=2, hardcopy=hardcopy)
plt.show()
except:
pass
try:
ig.plot_feature_2d(f_post_h5,im=1,iz=30, key='Median', uselog=1, cmap='jet', s=2, hardcopy=hardcopy)
plt.show()
except:
pass
try:
ig.plot_feature_2d(f_post_h5,im=1,iz=50, key='Median', uselog=1, cmap='jet', s=2,hardcopy=hardcopy)
plt.show()
except:
pass
/M1/Median[5,:] resistivity
/M1/Median[30,:] resistivity
/M1/Median[50,:] resistivity
[18]:
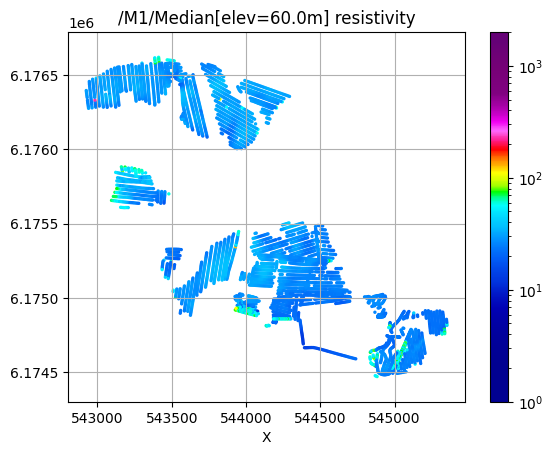
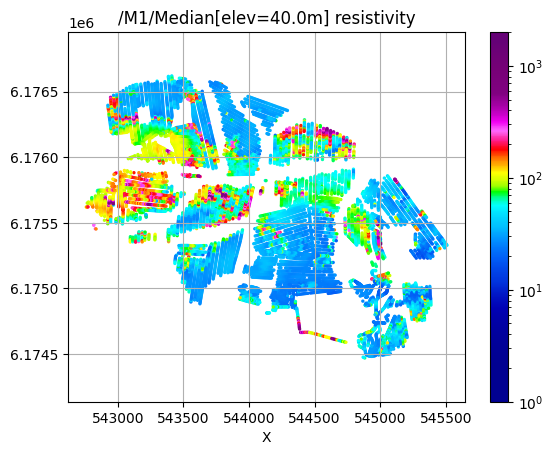
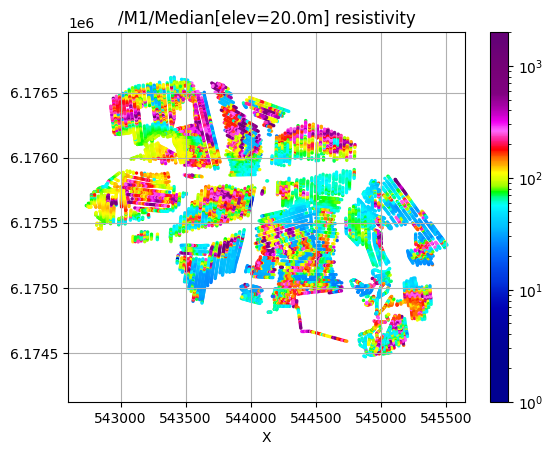
# Plot 2D features: Resistivity at different elevations
try:
for ele in np.arange(60,-51,-20):
plt.figure()
ig.plot_feature_2d(f_post_h5,im=1,elevation=ele, key='Median', uselog=1, clim=[1,2000],s=2, hardcopy=hardcopy)
plt.show()
except:
pass
/M1/Median[elev=60.0m] resistivity
/M1/Median[elev=40.0m] resistivity
/M1/Median[elev=20.0m] resistivity
/M1/Median[elev=0.0m] resistivity
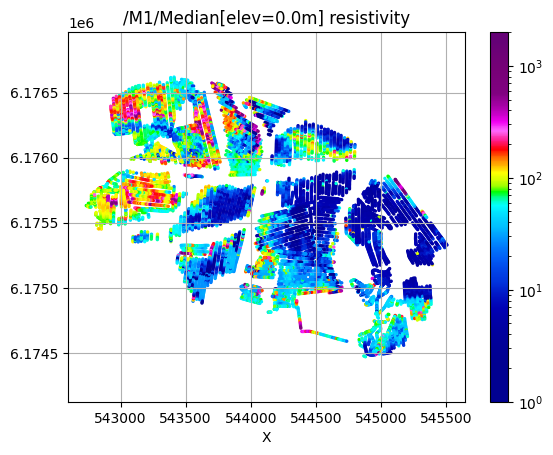
/M1/Median[elev=-20.0m] resistivity
/M1/Median[elev=-40.0m] resistivity
[19]:
try:
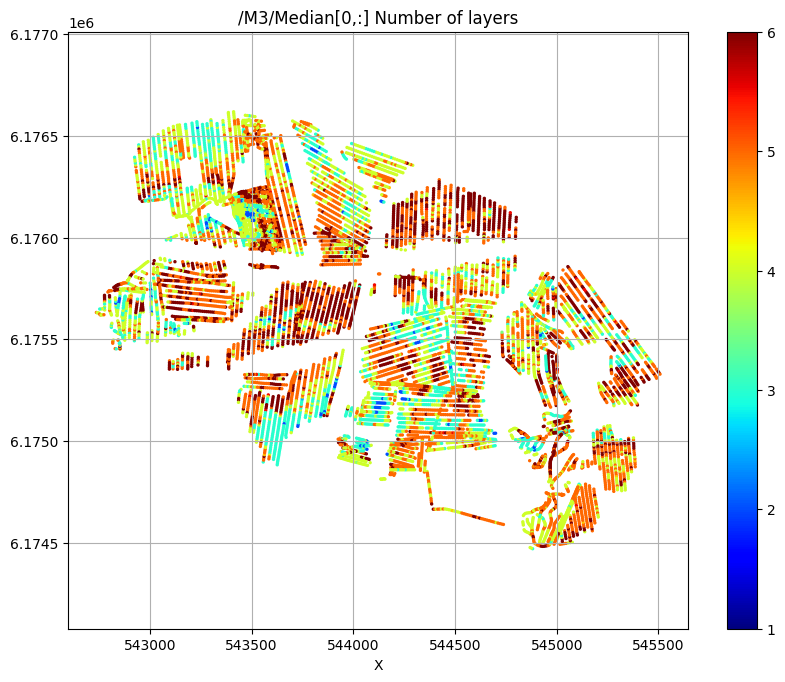
# Plot a 2D feature: The estimated number of layers
ig.plot_feature_2d(f_post_h5,im=3,iz=0,key='Median', uselog=0, clim=[1,6], cmap='jet', s=2,hardcopy=hardcopy)
plt.show()
except:
pass
/M3/Median[0,:] Number of layers
Export results to CSV format¶
Export the posterior results to CSV files for use in GIS software or further analysis.
[20]:
f_csv, f_point_csv = ig.post_to_csv(f_post_h5)
Writing to POST_M1.csv
----------------------------------------------------
Creating point data set: Median
Creating point data set: Mean
Creating point data set: Std
- saving to : POST_M1_point.csv
[21]:
# Read the exported CSV file for inspection
# Example filename (actual filename will be generated automatically):
#f_point_csv = 'POST_DAUGAARD_AVG_PRIOR_CHI2_NF_3_log-uniform_N100000_TX07_20231016_2x4_RC20-33_Nh280_Nf12_Nu100000_aT1_M1_point.csv'
import pandas as pd
df = pd.read_csv(f_point_csv)
df.head()
[21]:
| X | Y | Z | LINE | Median | Mean | Std | |
|---|---|---|---|---|---|---|---|
| 0 | 543822.9 | 6176069.6 | 58.82 | 140.0 | 19.465492 | 25.206160 | 0.179736 |
| 1 | 543822.9 | 6176069.6 | 57.82 | 140.0 | 19.687078 | 25.983789 | 0.167448 |
| 2 | 543822.9 | 6176069.6 | 56.82 | 140.0 | 19.802555 | 24.798481 | 0.149210 |
| 3 | 543822.9 | 6176069.6 | 55.82 | 140.0 | 19.836796 | 20.938669 | 0.116562 |
| 4 | 543822.9 | 6176069.6 | 54.82 | 140.0 | 19.836796 | 20.805281 | 0.108862 |
[22]:
# Optional: Use PyVista for 3D visualization of X,Y,Z coordinates with median resistivity
plPyVista = False
if plPyVista:
import pyvista as pv
import numpy as np
from pyvista import examples
#pv.set_jupyter_backend('client')
pv.set_plot_theme("document")
p = pv.Plotter(notebook=True)
p = pv.Plotter()
filtered_df = df[(df['Median'] < 50) | (df['Median'] > 200)]
#filtered_df = df[(df['LINE'] > 1000) & (df['LINE'] < 1400) ]
points = filtered_df[['X', 'Y', 'Z']].values[:]
median = np.log10(filtered_df['Mean'].values[:])
opacity = np.where(filtered_df['Median'].values[:] < 100, 0.5, 1.0)
#p.add_points(points, render_points_as_spheres=True, point_size=3, scalars=median, cmap='jet', opacity=opacity)
p.add_points(points, render_points_as_spheres=True, point_size=6, scalars=median, cmap='hot')
p.show_grid()
p.show()